Accelerating Inference on Qualcomm Processors with Muna
We spent months inside the QNN SDK so you don't have to.
Feb 26, 2026
As part of an upcoming launch with one of our partners, we spent a significant amount of time working with Qualcomm's QNN SDK. It is Qualcomm's toolkit for converting and deploying models onto its suite of neural processors, including the Adreno GPU and the Hexagon Tensor Processor.
The SDK is notoriusly difficult to work with, so much so that Qualcomm offers a wrapper service to use it. We're happy to share that you can now compile a PyTorch model for Qualcomm CPUs, GPUs, and Hexagon NPUs with Muna.
Qualcomm Processors Remains Inaccessible to Most Developers
There are over 2.5 billion Qualcomm processors in the world today, contained in personal computers, mobile devices, automotives, and much more. Unfortunately, most developers are unable to leverage these processors to accelerate AI inference workloads today.
Qualcomm provides the QNN SDK (formally "Qualcomm AI Engine Direct"). It is a capable, low-level toolkit for bringing AI models into their ecosystem. It is also extremely complex to work with: The SDK ships as a 2GB archive, and once extracted, it contains an encyclopedia's worth of information to digest and make use of:

Cross-compiling neural network graphs for heterogeneous hardware is genuinely hard systems work. But for teams shipping products, the gap between "I have a PyTorch model" and "it runs on a Snapdragon NPU" should be measured in minutes, not weeks.
Using the Qualcomm Inference Metadata
Muna allows developers to compile AI models by decorating a Python function with our @compile decorator, and running our muna compile CLI command. The decorator accepts optional metadata objects, which give the compiler hints. We have added the QnnInferenceMetadata metadata type to inform the compiler to lower a PyTorch model to a Qualcomm deep learning container (DLC).
The backend argument allows for specifying the Qualcomm hardware accelerator target. And there is an optional quantization argument that allows for specifying which quantization scheme to use when targeting the Hexagon NPU (htp).
That is the entire surface. No environment variables. No SDK install on your machine. No Hexagon toolchain. Our compiler handles model export, conversion, context binary generation, and packaging internally.
Performance Benchmarks
The QNN GPU and HTP backends typically outperform the CPU backend by a wide margin. At small batch sizes, the GPU wins on raw compute throughput:
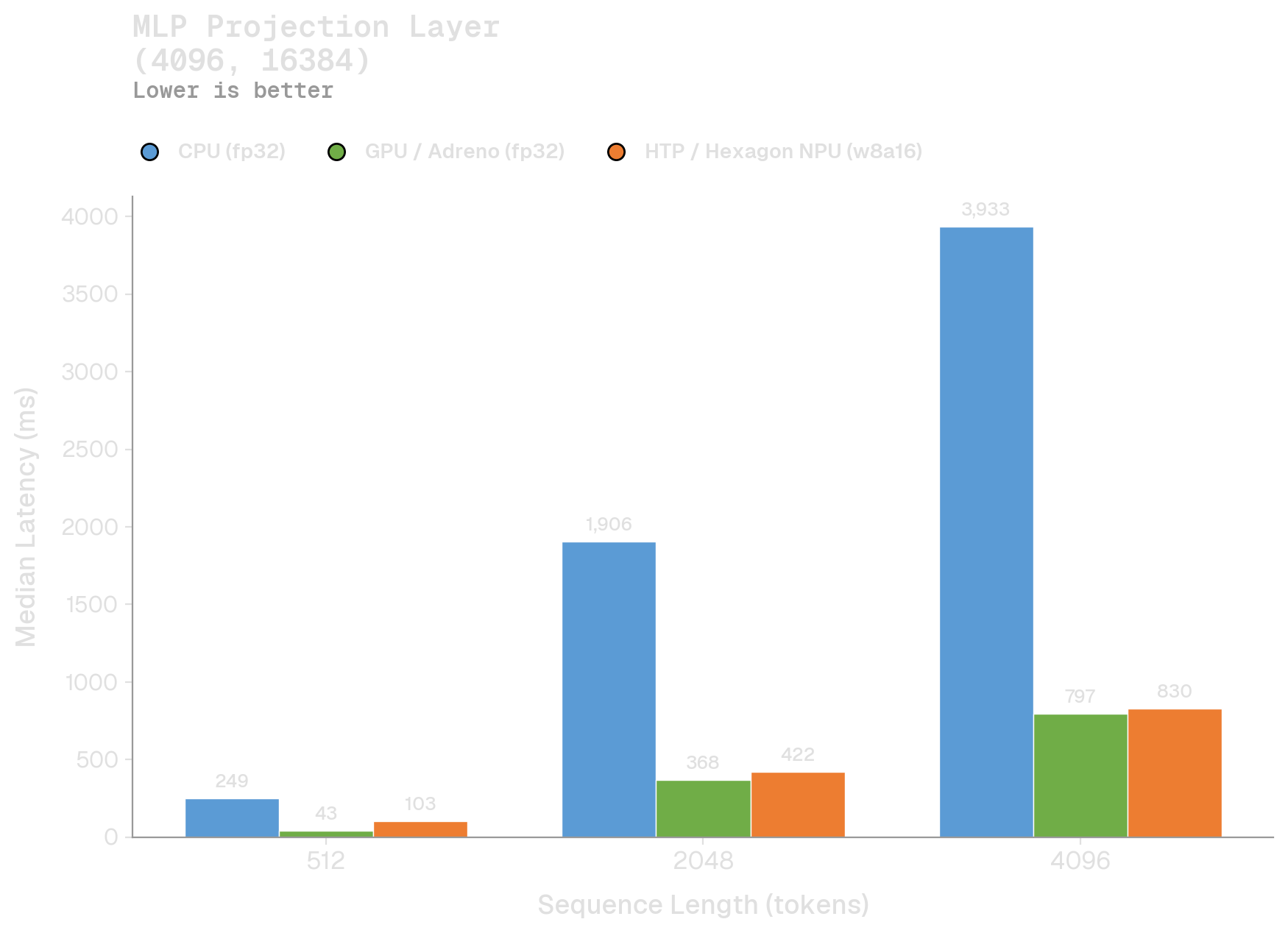
But as batch sizes grow, and the bottleneck shifts from compute to memory bandwidth, the NPU is clearly favored. This is apparent in the NPU's linear scaling as the batch size doubles, as compared to superlinear scaling for both the CPU and GPU. We also ran a benchmark against ONNXRuntime:
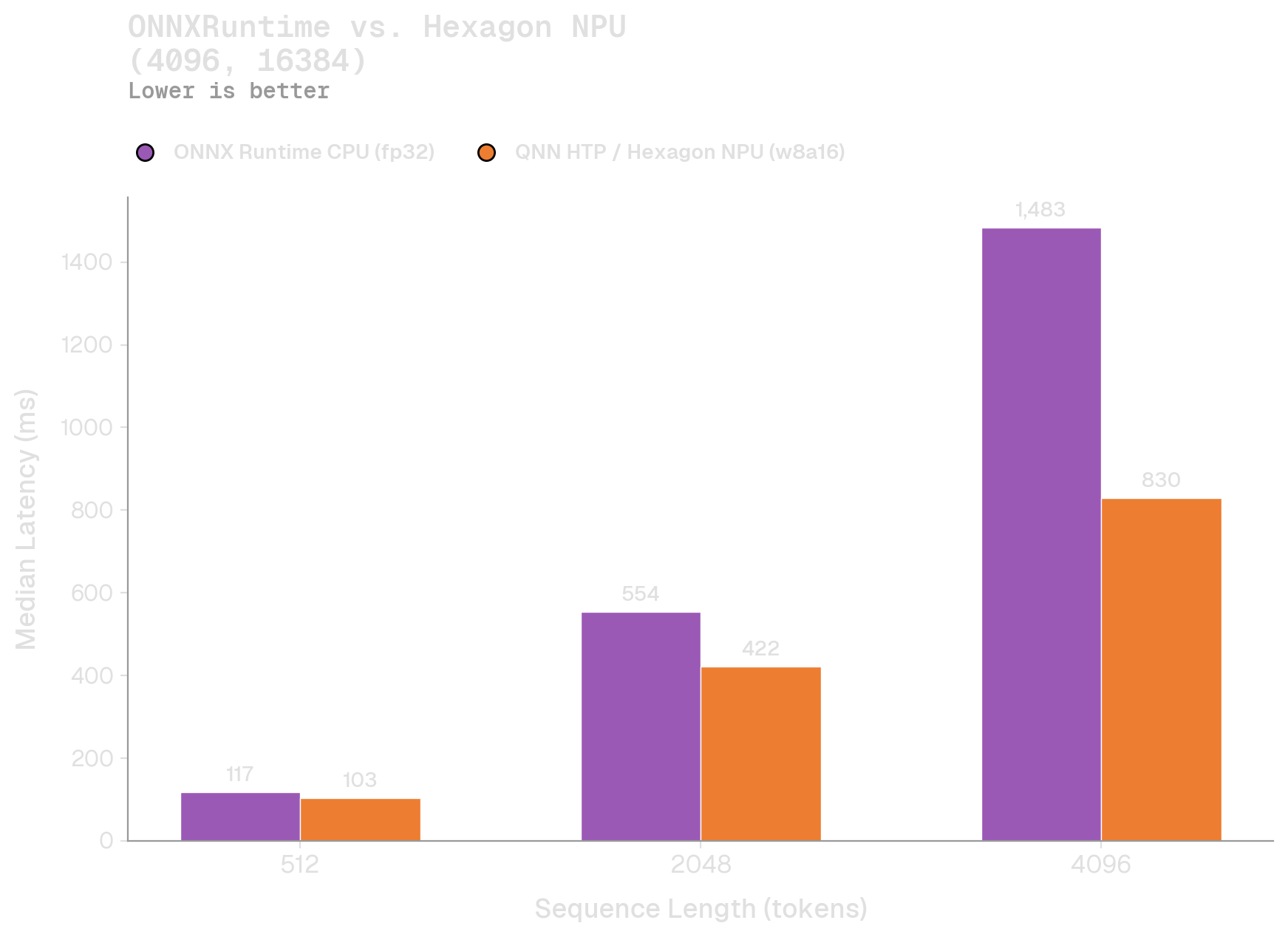
Overall, it's clear that developers should offload as much compute to the Hexagon NPU. Today, our integration makes this seamless.
Moving Beyond Convenience
The QNN SDK is complex, but for good reason: target-specific compilation, quantization calibration, backend-specific graph lowering. These are real problems that someone has to solve. The question is whether every team deploying to Qualcomm hardware should have to solve them independently, or whether the solution can be shared infrastructure. We think it is the latter.
We would like to thank the team at Nomic for collaborating on this feature. If you are working on on-device inference for Qualcomm hardware (mobile, automotive, IoT), we would like to hear from you. Reach out at hi@muna.ai or join our Slack.