Pioneering Private, Local Document Intelligence with Nomic Layout
Extract valuable data from complex documents with nomic-layout-v1.
Apr 8, 2026
Today, Nomic is launching its newest offering in its line of leading open-source
models: nomic-layout-v1. This is a layout parsing model, capable of breaking
down complex documents into contextual chunks for downstream processing.
Over the past few months, we have collaborated with Nomic to ensure that developers can run these models on a wide variety of devices, with peak performance. Let's jump in:
Layout Parsing as the First Step
Much of the world's knowledge exists in documents: PDFs and scans of physical documents. This data is unstructured, meaning that LLMs and AI agents cannot efficiently reason over them. Layout parsing takes a document, and extracts structural elements from each page. The model efficiently identifies and localizes things like titles, sections, tables, paragraphs, and so on.
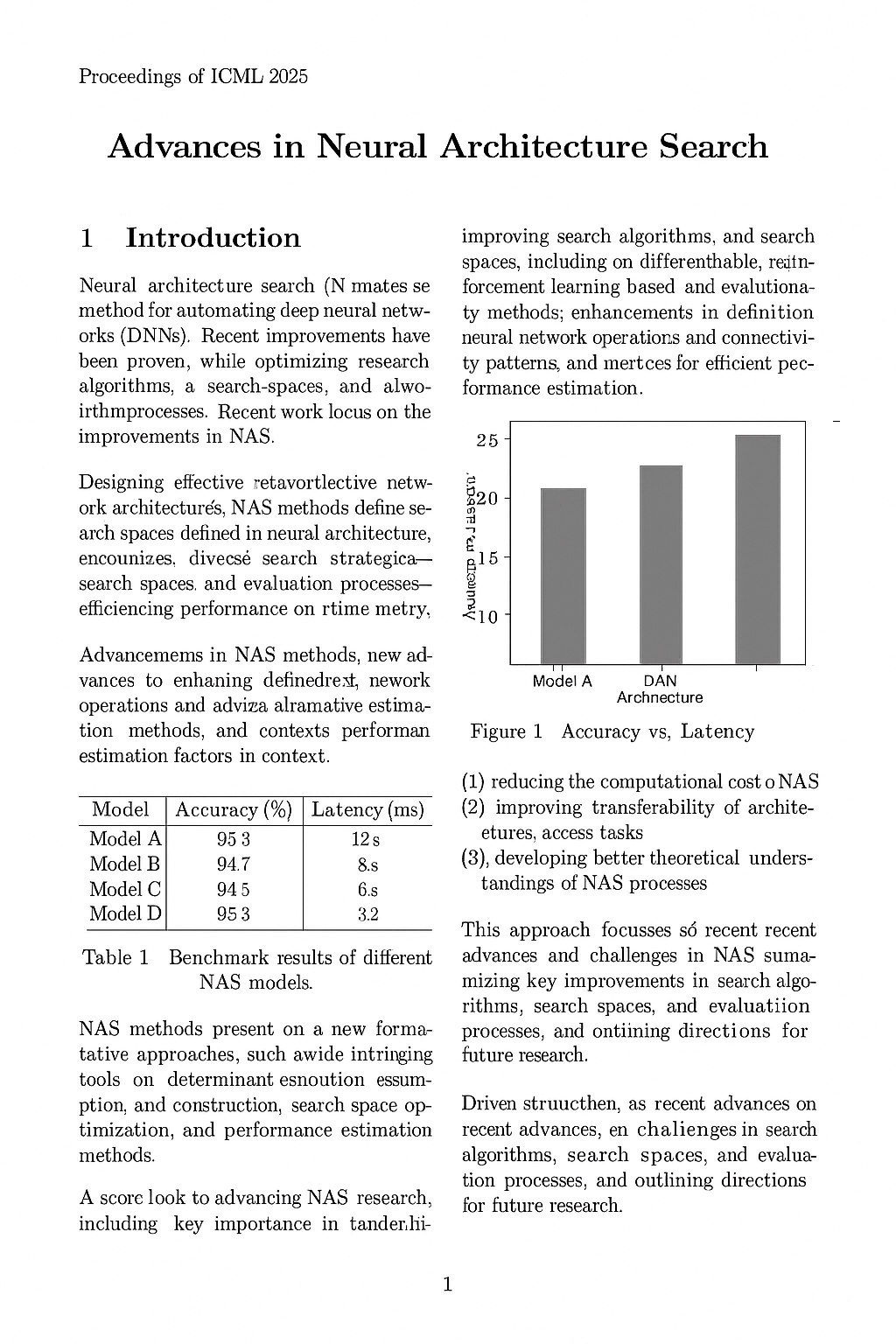
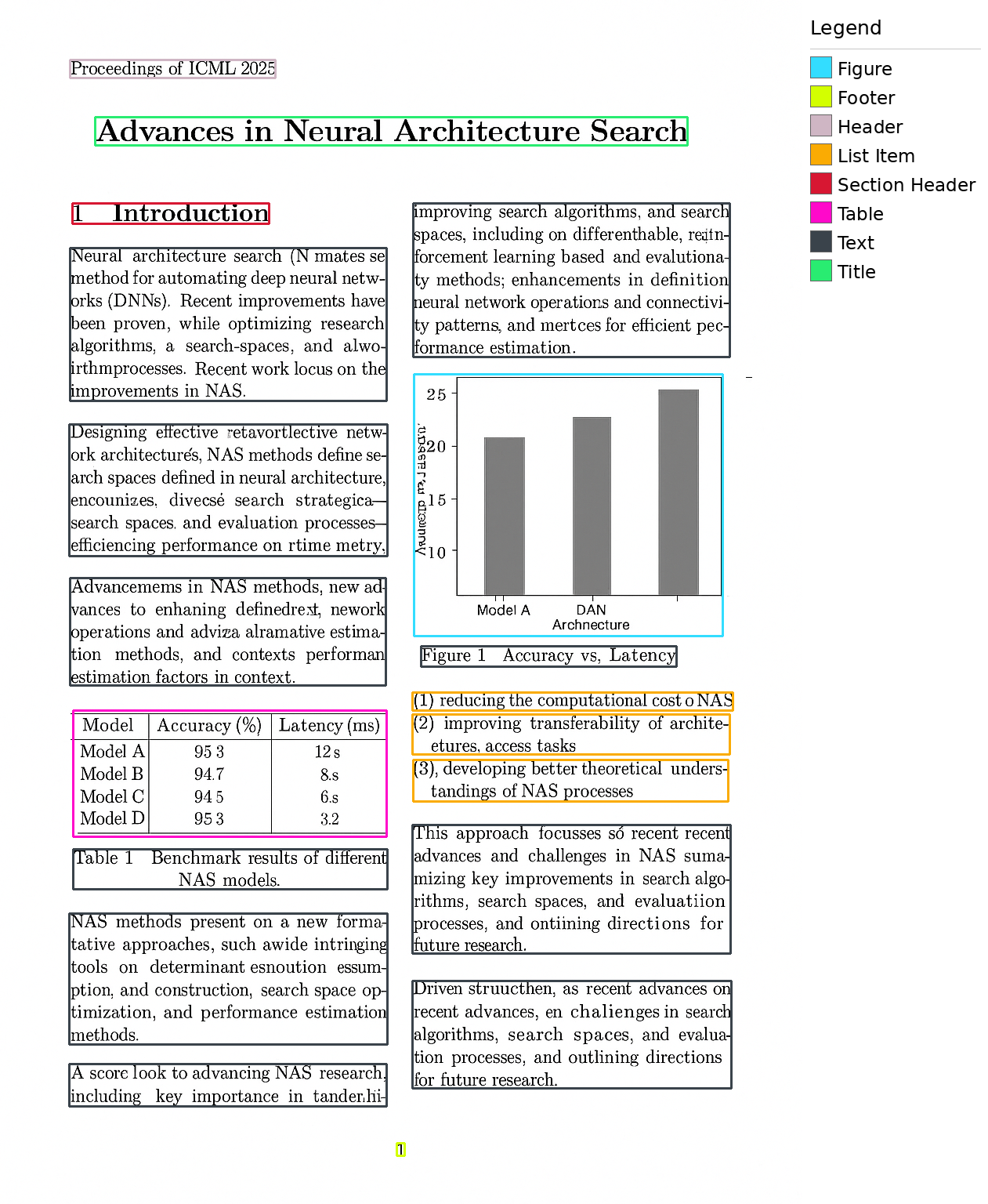
nomic-layout-v1 detects 9 element types, allowing for extremely efficient downstream processing. Images can be extracted and captioned; tables can be run through text recognition; and so on. Building such a pipeline is significantly faster and cheaper than feeding entire pages into an LLM; and running it locally means sensitive documents never leave the device.
Enabling Agentic Document Retrieval with Skills
Enterprise teams routinely need to extract specific information from large document collections: quarterly filings, vendor contracts, compliance records, and so on. To make this model as accessible as possible, we decided to create an Agent Skill: a lightweight, portable set of instructions that any coding agent can install and use.
Rather than requiring teams to set up a standalone pipeline or integrate a new API, the skill drops directly into tools like Claude Code and Cursor. Simply install the skill, point your agent to a directory, ask a question. The skill runs layout parsing locally, builds a local index, and feeds relevant data back to the agent including citations for further agentic retrieval.
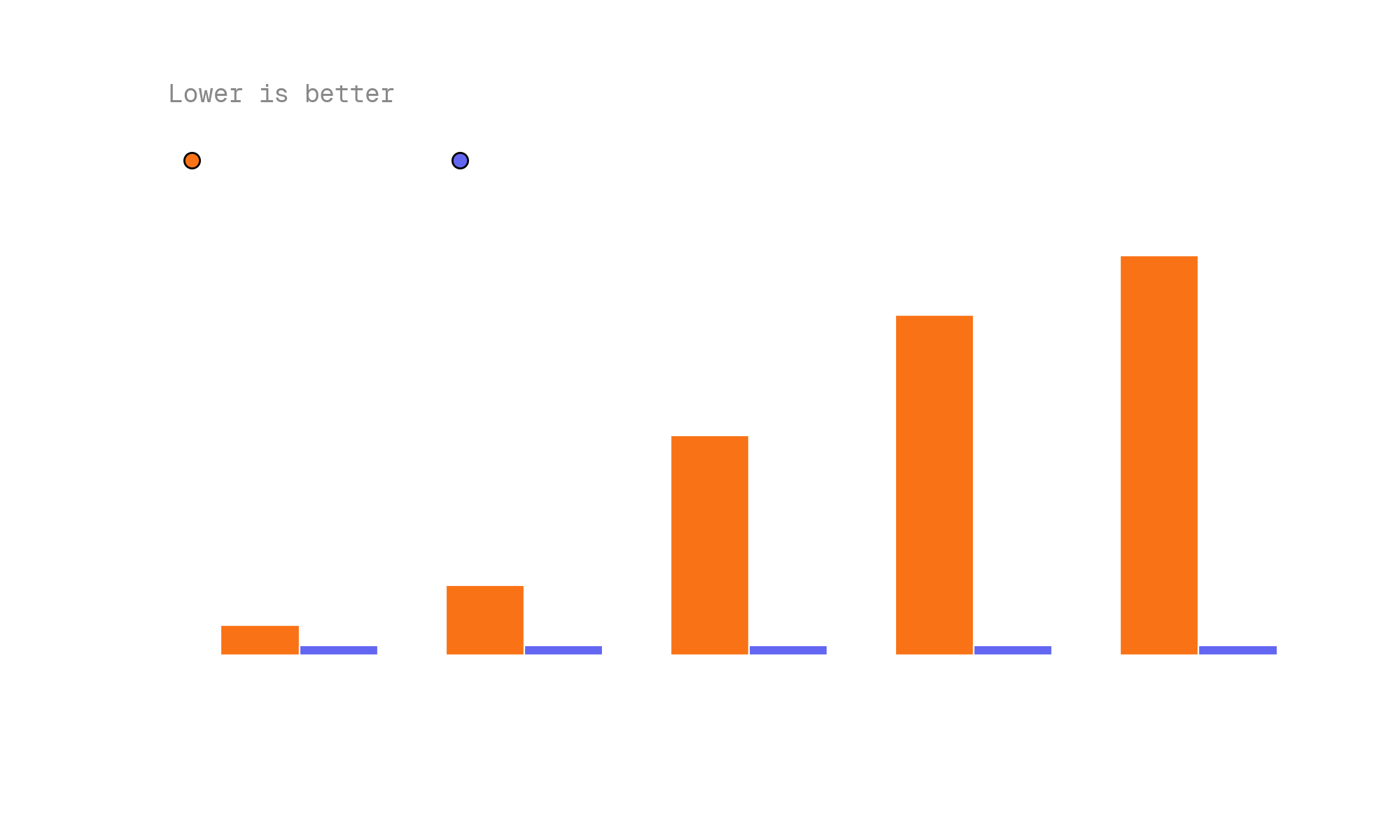
The results speak for themselves: up to 20x faster answers, consuming 40x fewer tokens compared to having the agent send the documents to remote servers for processing. And all of this parsing and indexing runs locally. Below, we discuss how we leveraged Muna's compiler platform to make the model multi-platform.
Enabling High-Performance, Multi-Platform Inference
With Muna, developers can write their inference logic as a standard Python function, then compile it to run across a wide range of hardware targets.
In compiling nomic-layout-v1, we wanted to both ensure wide compatibility and high performance on dedicated accelerators, like the Apple Silicon GPU and Qualcomm Hexagon Tensor Processor. To do so, we leveraged Muna's inference metadata feature, directing the compiler to use MLX on Apple Silicon and QNN on Qualcomm Snapdragon processors.
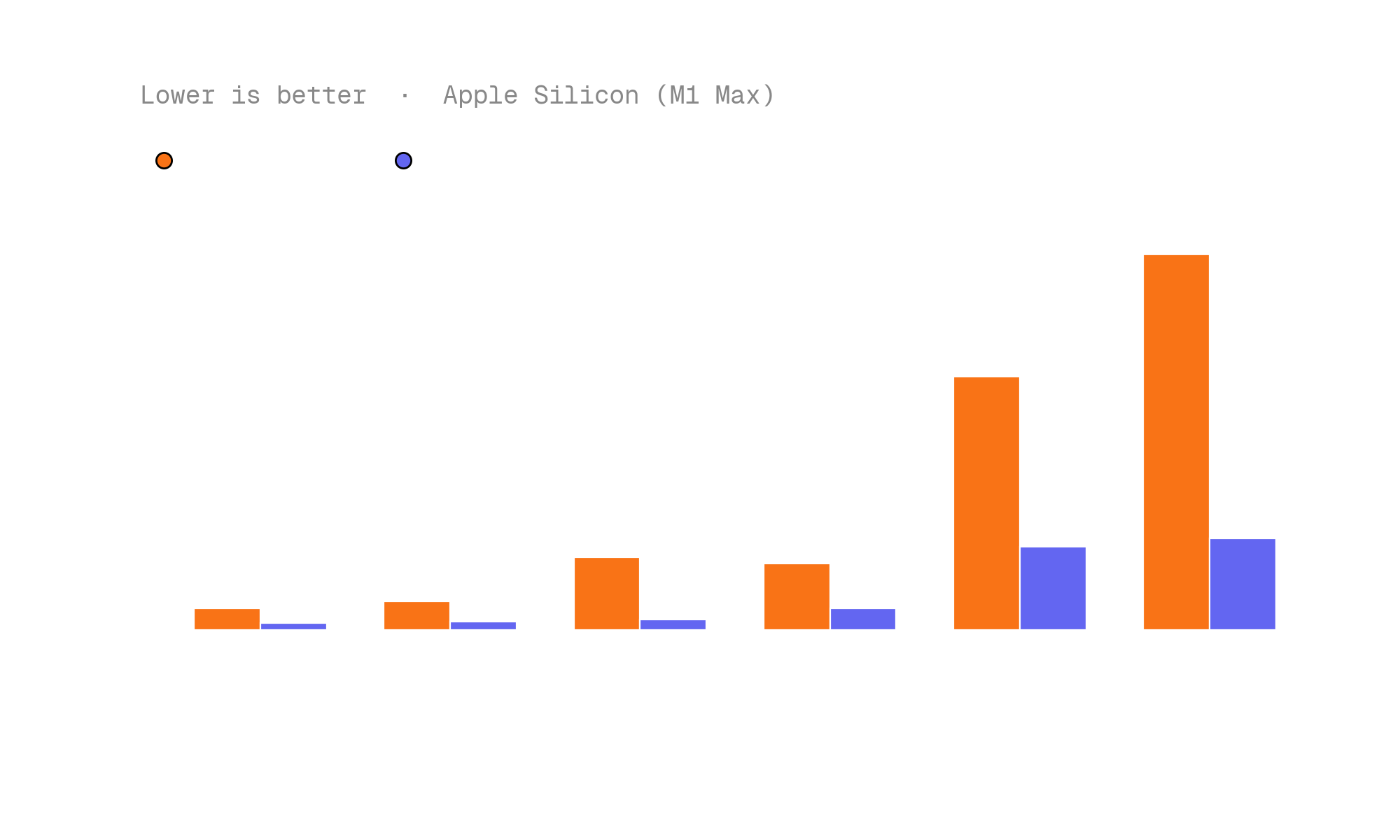
The results are up to 4x latency improvements over the CPU baseline on Apple Silicon, and 9x on the Qualcomm Hexagon Tensor Processor:
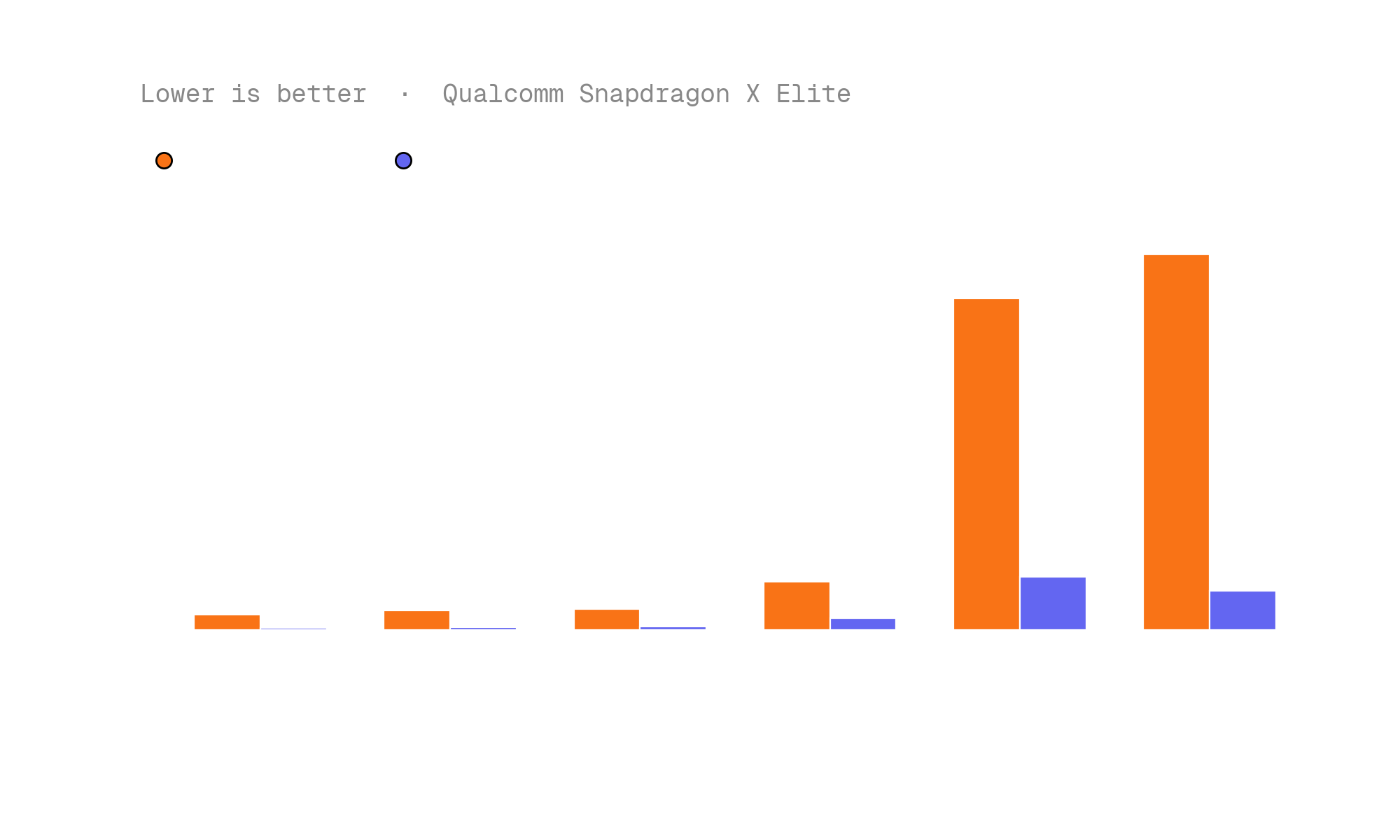
The takeaway is simple: the same Python function, compiled once, runs with native performance on every target device — from MacBooks to Qualcomm-powered PCs to datacenter GPUs — with zero porting effort from the developer.
On the Future of Fully Private Document Intelligence
With nomic-layout-v1, teams can process documents intelligently—extracting structure, answering questions, building indexes—with significantly less compute and cost than feeding pages into an LLM. And because the entire pipeline runs on-device, sensitive documents never leave the machine. For regulated industries like legal, healthcare, and finance, this means adopting AI-powered document workflows without compromising on data privacy.
Try out the web demo or agent skill above. And if you are interested in deploying this within your organization, reach out to us.